ملف robots.txt: مشكلة تحسين محركات البحث التي تم تجاهلها
سؤال
في الشهر الماضي، استخدمت nextjs لإنشاء موقعين على الويب، لكنني لم أهتم بهما منذ ذلك الحين. لقد وجدت مؤخرًا أن حالة تضمين Google لهذين الموقعين ليست جيدة. لقد ألقيت نظرة فاحصة اليوم ووجدت أن هناك مشكلة في ملف robots.txt.
التحقق من عنوان URL غير المضمن في GSC، تكون النتائج كما يلي
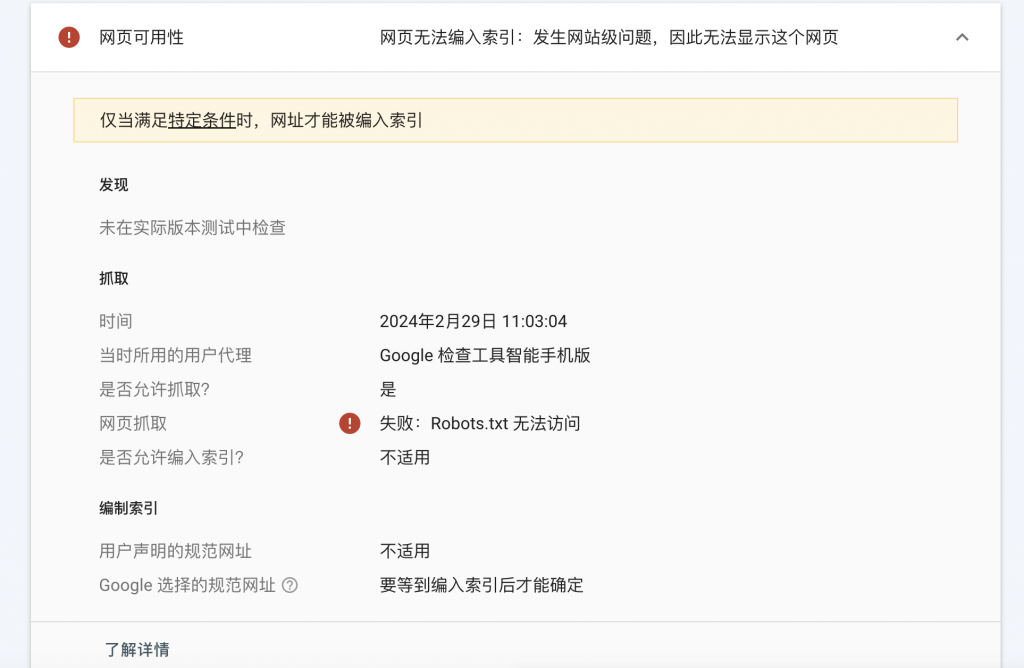
في السنوات الأخيرة، عند إنشاء مواقع الويب، يستخدم معظمها أنظمة إدارة المحتوى (CMS) الناضجة، مثل WordPress وما إلى ذلك، وليس هناك حاجة للنظر في مسألة ملف robots.txt، لذلك تم تجاهل ملف robots.txt دائمًا.
استخدمت هذه المرة nextjs لبناء موقع الويب، وقد لاحظت هذه المشكلة.
حل
أضف ملف robots.txt.
1. أضف ملف robots.txt إلى دليل التطبيق لمشروع nextjs
2. أضف القواعد التالية إلى ملف robots.txt
وكيل المستخدم: * السماح: / عدم السماح: /خاص/ خريطة الموقع: https://www.xxx.com/sitemap.xmlيوضح:
"User-Agent: *": يشير إلى أن جميع برامج الزحف يمكنها الوصول إلى موقع الويب.
"السماح: /": يسمح بالوصول إلى كافة المحتويات.
"عدم السماح: /خاص/": يشير إلى أن الوصول إلى الدليل الخاص غير مسموح به.
3. قم بإجراء الاختبار مرة أخرى بعد الانتهاء
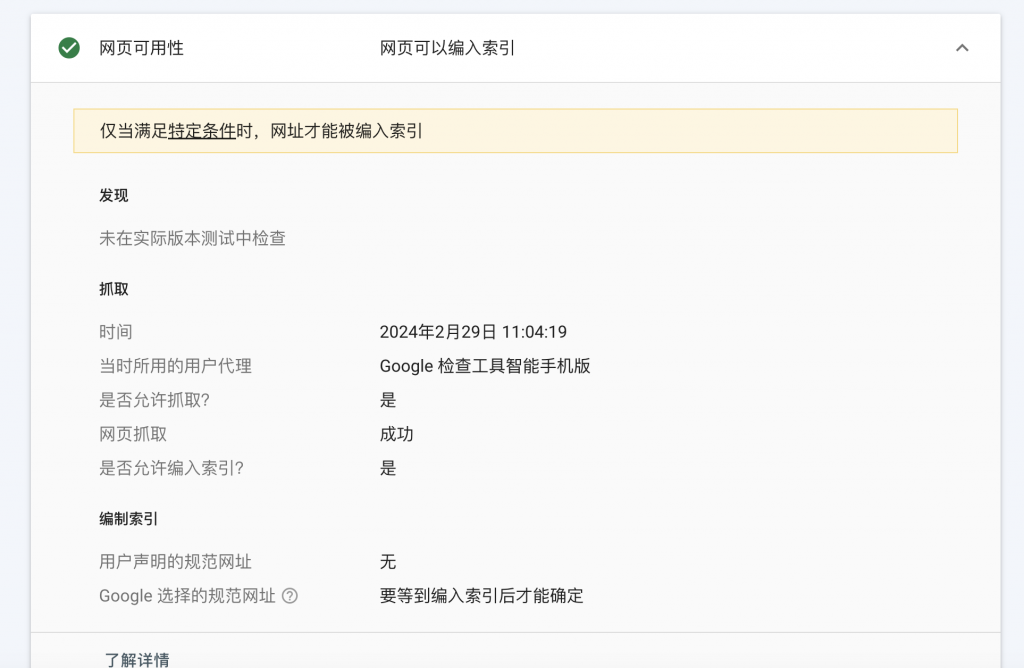
لخص
سيؤثر غياب ملف robot.txt بشكل كبير على تضمين المحتوى بواسطة محركات البحث.
تشير إلى
كيفية الإصلاح: يمنع ملف Robots.txt الزحف إلى صفحات سطح المكتب – مساعدة Google Merchant Center
ملف البيانات الوصفية: robots.txt |Next.js (nextjs.org)

关注我的微信公众号
