robots.txt: Et SEO-problem, der er blevet ignoreret
After constructing two sites with Next.js last month and noticing poor Google indexation, the issue was identified as a missing robots.txt file. To address this, a robots.txt with rules to allow all user-agents, enable access to all content excluding the 'private' directory, and link a sitemap was added to the Next.js app directory. This resolved the indexing issue, underscoring the importance of robots.txt for site visibility.
问题
上个月,用nextjs做了两个站,之后一直没管。最近发现这两个站在Google的收录情况都不好。今天仔细看了一下,发现是robots.txt的问题。
在GSC中检查一个没有被收录的URL,结果如下
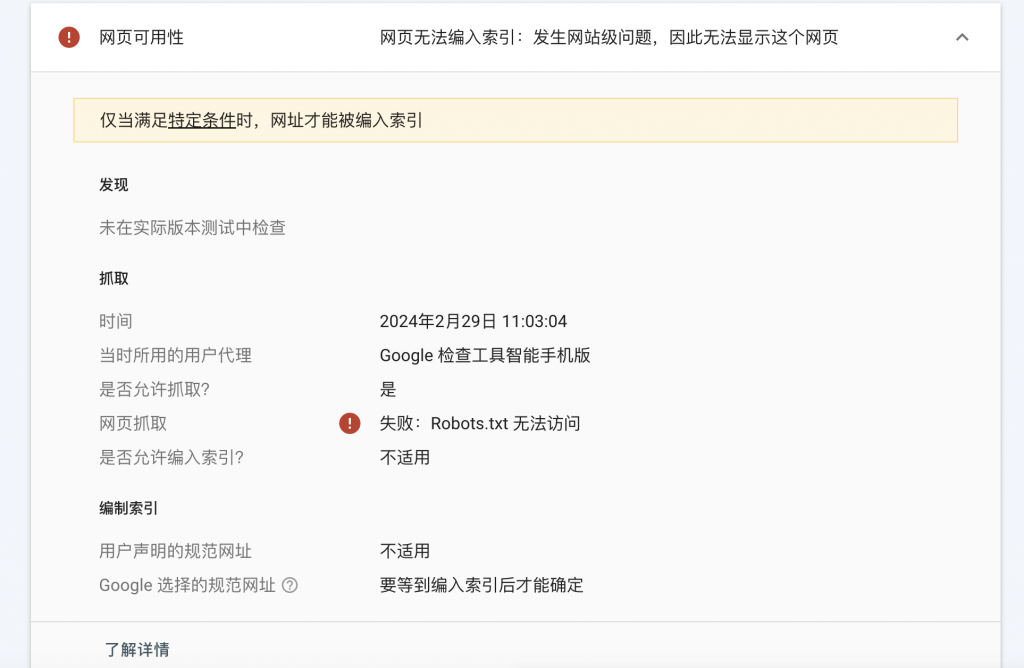
这些年,做站,大多是用成熟的cms,比如Wordpress等,不必考虑robots.txt的问题,所以,对robots.txt一直都是忽略的状态。
这次用nextjs做站,才注意到这个问题。
解决方法
增加robots.txt文件。
1、在nextjs项目的app目录中增加robots.txt文件
2、在robots.txt文件中增加以下规则
User-Agent: *
Allow: /
Disallow: /private/
Sitemap: https://www.xxx.com/sitemap.xml说明:
“User-Agent: *”:表示所有的爬虫都可以访问网站。
“Allow: /”:表示允许访问所有内容。
“Disallow: /private/”:表示不允许访问private目录。
3、完成后再次测试
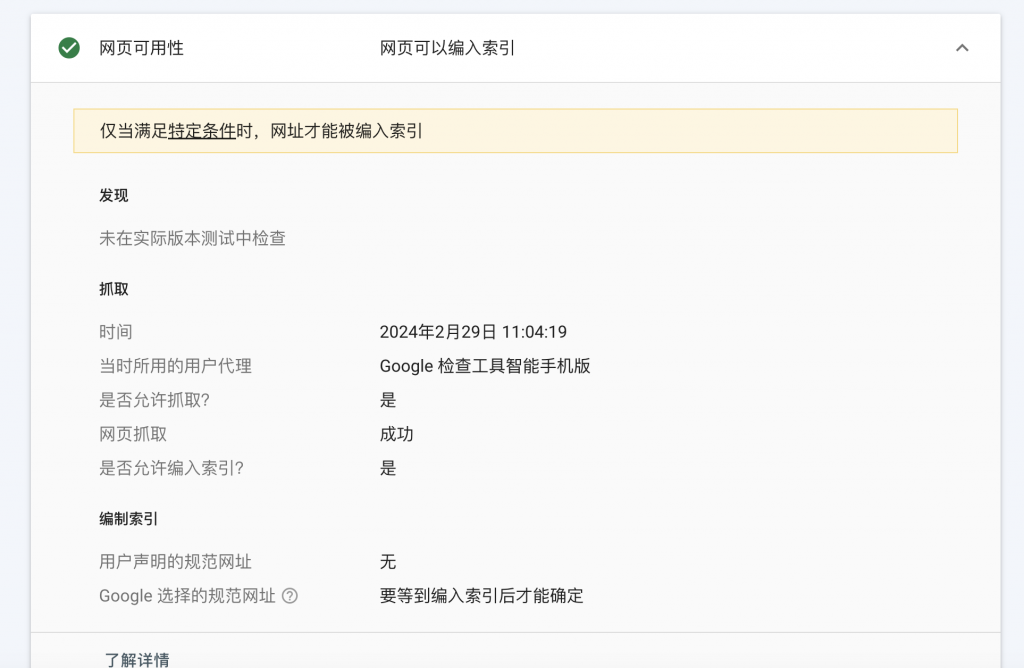
Sammenfatte
robot.txt文件缺失会从很大程度上影响搜索引擎对内容的收录。
henvise til
如何解决:robots.txt 导致无法抓取桌面版页面 – Google Merchant Center帮助
元数据文件:robots.txt |Next.js (nextjs.org)

关注我的微信公众号
