robots.txt: Ein SEO-Problem, das ignoriert wurde
Frage
Letzten Monat habe ich nextjs verwendet, um zwei Websites zu erstellen, aber seitdem habe ich mich nicht mehr damit beschäftigt. Kürzlich habe ich festgestellt, dass der Google-Einbindungsstatus dieser beiden Websites nicht gut ist. Ich habe heute genauer hingeschaut und festgestellt, dass es sich um ein Problem mit robots.txt handelt.
Bei der Überprüfung einer URL, die nicht in GSC enthalten ist, sind die Ergebnisse wie folgt
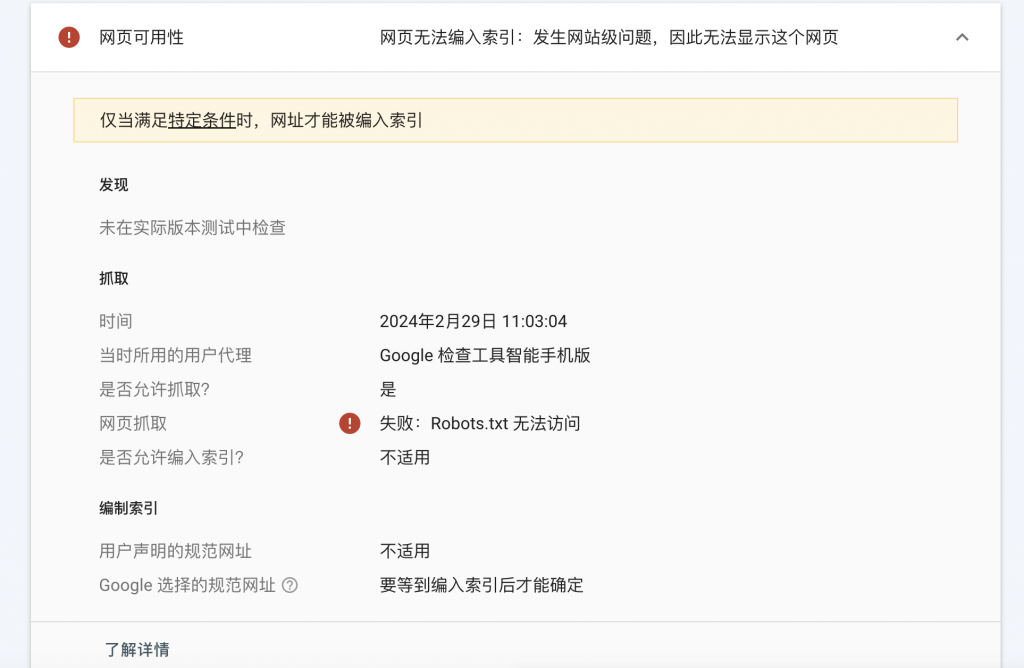
In den letzten Jahren verwenden die meisten von ihnen beim Erstellen von Websites ausgereifte CMS wie WordPress usw., und es besteht keine Notwendigkeit, das Problem von robots.txt zu berücksichtigen. Daher wurde robots.txt immer ignoriert.
Dieses Mal habe ich nextjs zum Erstellen der Website verwendet und dieses Problem bemerkt.
Lösung
Fügen Sie die robots.txt-Datei hinzu.
1. Fügen Sie die robots.txt-Datei zum App-Verzeichnis des nextjs-Projekts hinzu
2. Fügen Sie der robots.txt-Datei die folgenden Regeln hinzu
Benutzeragent: * Zulassen: / Nicht zulassen: /private/ Sitemap: https://www.xxx.com/sitemap.xmlveranschaulichen:
„User-Agent: *“: Zeigt an, dass alle Crawler auf die Website zugreifen können.
„Zulassen: /“: Ermöglicht den Zugriff auf alle Inhalte.
„Disallow: /private/“: Zeigt an, dass der Zugriff auf das private Verzeichnis nicht erlaubt ist.
3. Nach Abschluss erneut testen
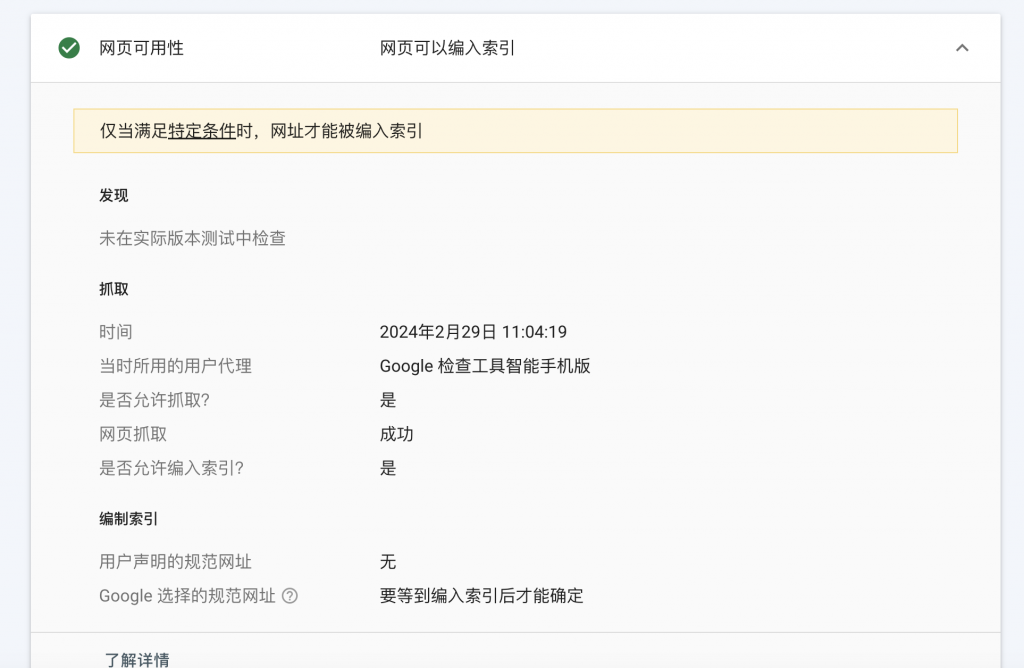
Zusammenfassen
Das Fehlen der robot.txt-Datei wird die Aufnahme von Inhalten durch Suchmaschinen stark beeinträchtigen.
beziehen auf
Metadatendatei: robots.txt |Next.js (nextjs.org)

关注我的微信公众号
