robots.txt: An SEO issue that has been ignored
question
Last month, I used nextjs to build two websites, but I haven’t bothered with them since. Recently I found that the Google inclusion status of these two sites is not good. I took a closer look today and found that it was a problem with robots.txt.
Checking a URL that is not included in GSC, the results are as follows
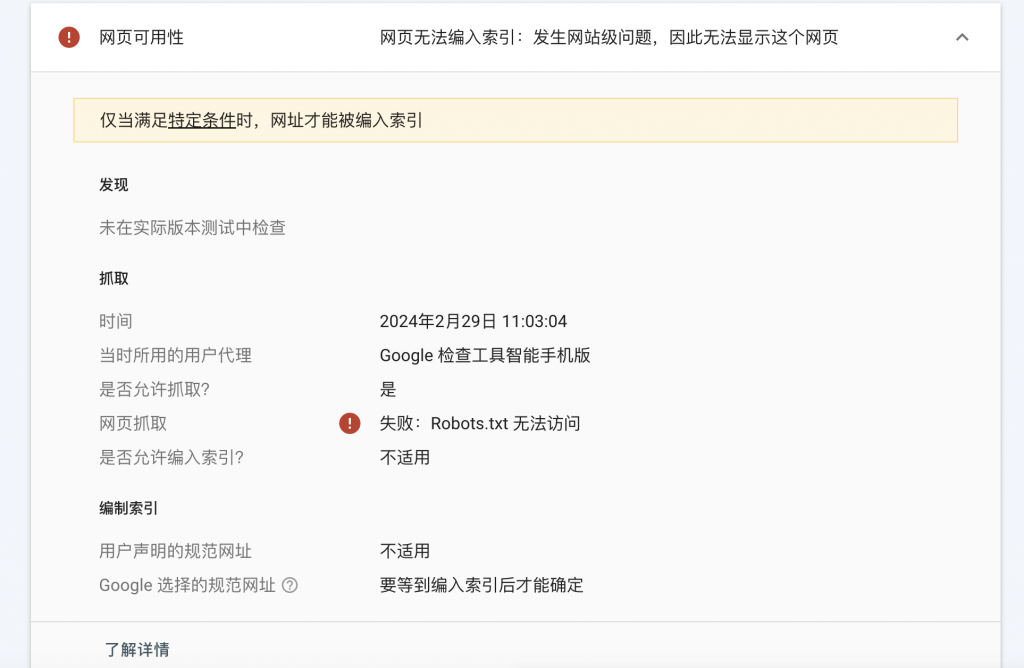
In recent years, when building websites, most of them use mature CMS, such as WordPress, etc., and there is no need to consider the issue of robots.txt. Therefore, robots.txt has always been ignored.
This time I used nextjs to build the website, and I noticed this problem.
Solution
Add robots.txt file.
1. Add the robots.txt file to the app directory of the nextjs project
2. Add the following rules to the robots.txt file
User-Agent: * Allow: / Disallow: /private/ Sitemap: https://www.xxx.com/sitemap.xmlillustrate:
"User-Agent: *": Indicates that all crawlers can access the website.
"Allow: /": Allows access to all content.
"Disallow: /private/": Indicates that access to the private directory is not allowed.
3. Test again after completion
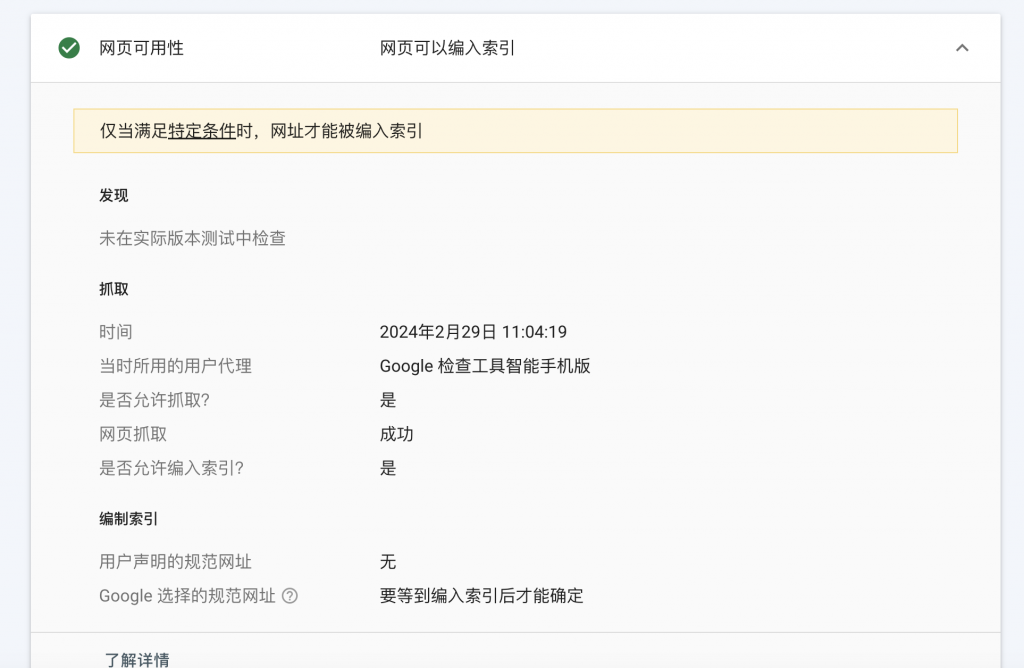
Summarize
The absence of the robot.txt file will greatly affect the inclusion of content by search engines.
refer to
How to fix: Robots.txt prevents desktop pages from being crawled – Google Merchant Center Help
Metadata file: robots.txt |Next.js (nextjs.org)

关注我的微信公众号
