robots.txt: Un problema de SEO que se ha ignorado
pregunta
El mes pasado, utilicé nextjs para crear dos sitios web, pero no me he molestado en utilizarlos desde entonces. Recientemente descubrí que el estado de inclusión de estos dos sitios en Google no es bueno. Hoy miré más de cerca y descubrí que era un problema con robots.txt.
Al verificar una URL que no está incluida en GSC, los resultados son los siguientes
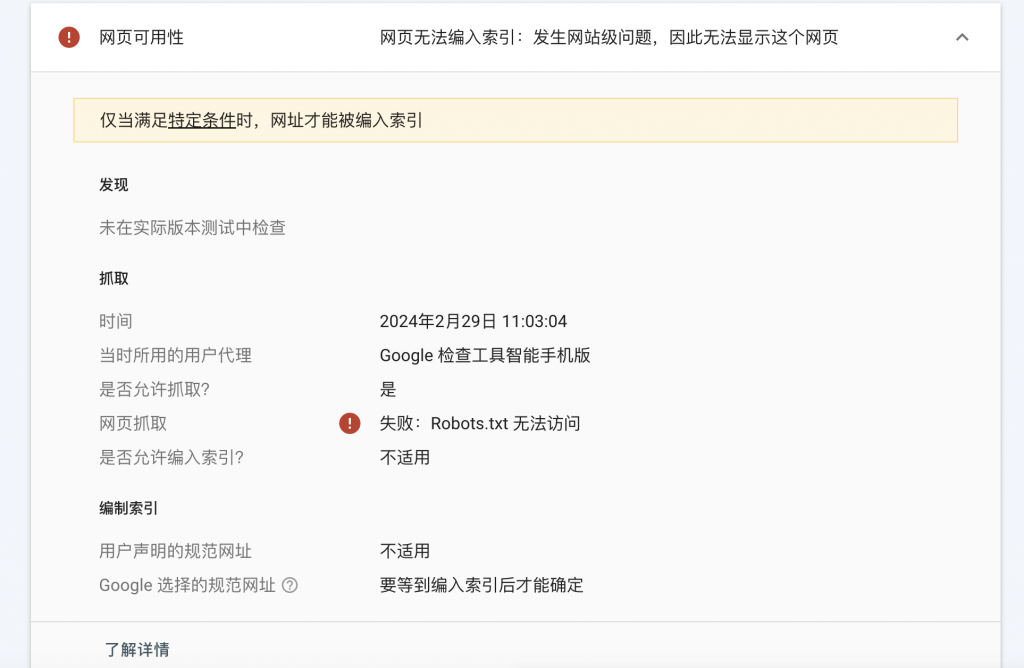
En los últimos años, al crear sitios web, la mayoría utiliza CMS maduros, como WordPress, etc., y no es necesario considerar el tema del robots.txt, por lo que siempre se ha ignorado el robot.txt.
Esta vez usé nextjs para crear el sitio web y noté este problema.
Solución
Agregue el archivo robots.txt.
1. Agregue el archivo robots.txt al directorio de la aplicación del proyecto nextjs.
2. Agregue las siguientes reglas al archivo robots.txt.
Agente de usuario: * Permitir: / No permitir: /privado/ Mapa del sitio: https://www.xxx.com/sitemap.xmlilustrar:
"User-Agent: *": Indica que todos los rastreadores pueden acceder al sitio web.
"Permitir: /": Permite el acceso a todo el contenido.
"Disallow: /private/": Indica que no se permite el acceso al directorio privado.
3. Pruebe nuevamente después de finalizar
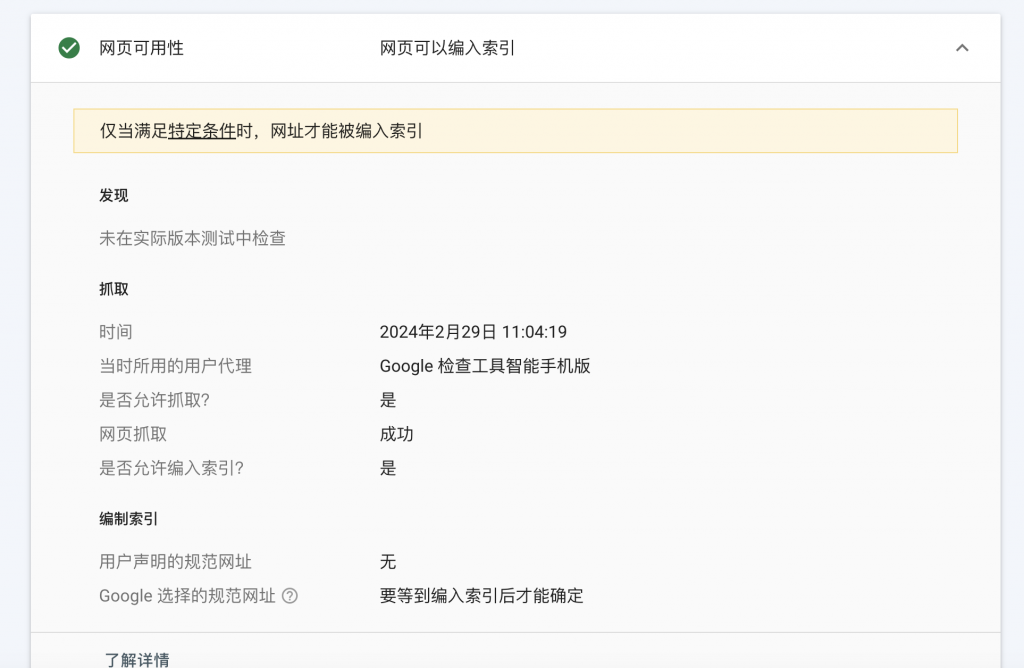
Resumir
La ausencia del archivo robot.txt afectará en gran medida a la inclusión de contenido por parte de los motores de búsqueda.
Referirse a
Archivo de metadatos: robots.txt |Next.js (nextjs.org)

关注我的微信公众号
