robots.txt : Un problème SEO qui a été ignoré
question
Le mois dernier, j'ai utilisé nextjs pour créer deux sites Web, mais je ne m'en suis plus soucié depuis. Récemment, j'ai découvert que le statut d'inclusion de ces deux sites sur Google n'était pas bon. J'ai regardé de plus près aujourd'hui et j'ai découvert qu'il s'agissait d'un problème avec robots.txt.
En vérifiant une URL qui n'est pas incluse dans GSC, les résultats sont les suivants
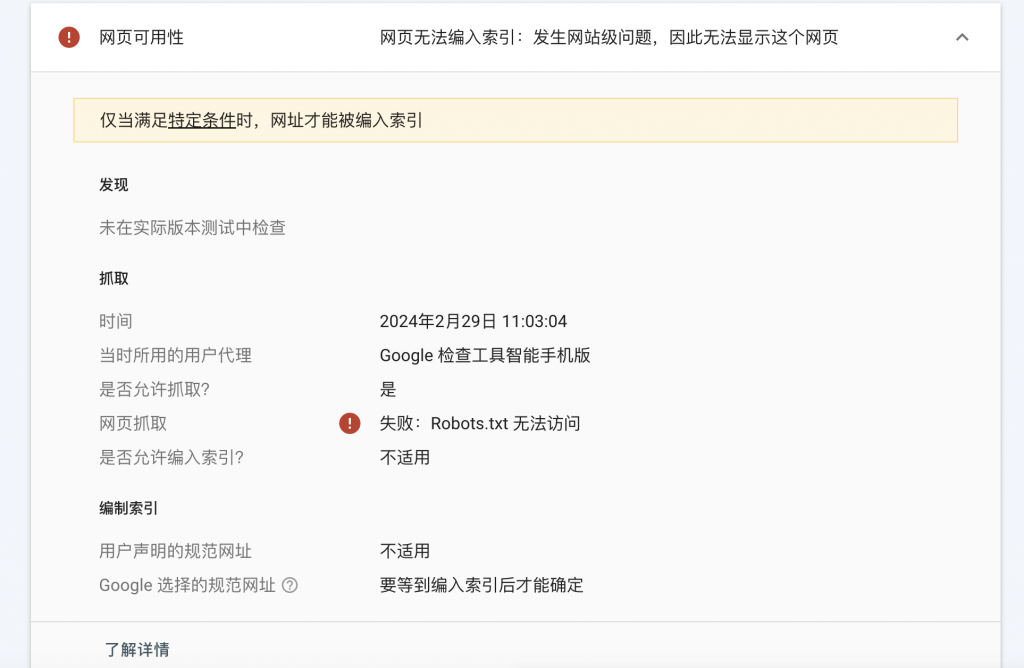
Ces dernières années, lors de la création de sites Web, la plupart d'entre eux utilisent des CMS matures, tels que WordPress, etc., et il n'est pas nécessaire de considérer la question du fichier robots.txt. Par conséquent, le fichier robots.txt a toujours été ignoré.
Cette fois, j'ai utilisé nextjs pour créer le site Web et j'ai remarqué ce problème.
Solution
Ajoutez le fichier robots.txt.
1. Ajoutez le fichier robots.txt au répertoire app du projet nextjs
2. Ajoutez les règles suivantes au fichier robots.txt
Agent utilisateur : * Autoriser : / Interdire : /private/ Plan du site : https://www.xxx.com/sitemap.xmlillustrer:
« User-Agent : * » : indique que tous les robots peuvent accéder au site Web.
« Autoriser : / » : autorise l'accès à tout le contenu.
"Disallow: /private/" : Indique que l'accès au répertoire privé n'est pas autorisé.
3. Testez à nouveau une fois terminé
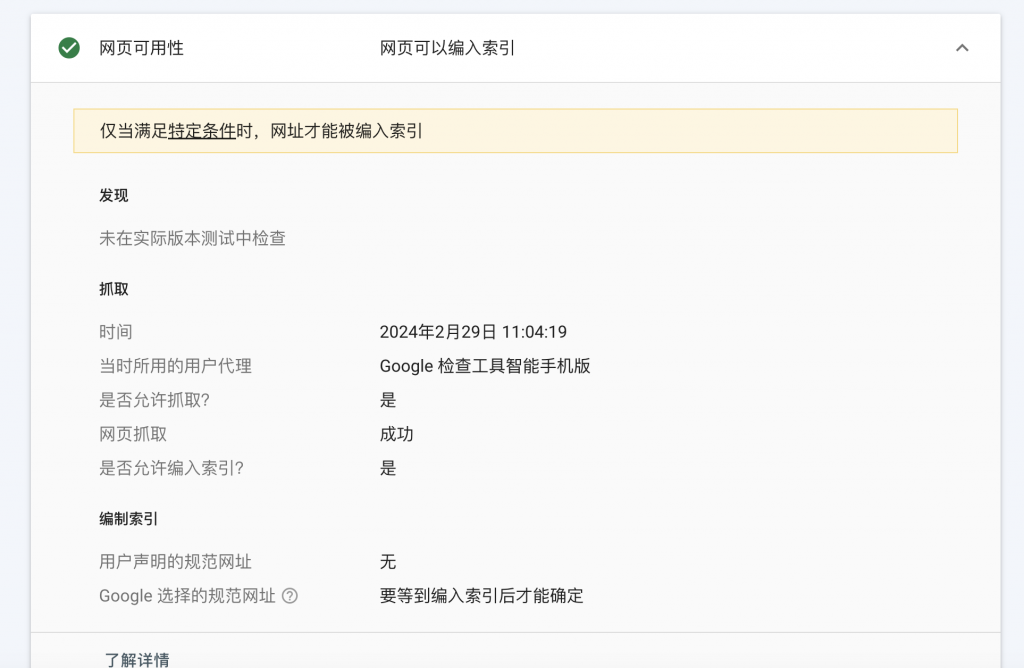
Résumer
L'absence du fichier robot.txt affectera grandement l'inclusion du contenu par les moteurs de recherche.
faire référence à
Fichier de métadonnées : robots.txt |Next.js (nextjs.org)

关注我的微信公众号
