robots.txt: 無視されてきた SEO の問題
先月 Next.js を使用して 2 つのサイトを構築し、Google のインデックス付けが不十分であることに気づいた後、問題は robots.txt ファイルの欠落であることが判明しました。これに対処するには、すべてのユーザー エージェントを許可するルールを備えた robots.txt で、すべてのコンテンツへのアクセスを有効にします。 「private」ディレクトリを除外し、サイトマップのリンクを Next.js アプリ ディレクトリに追加しました。これにより、インデックス作成の問題が解決され、サイトの可視性にとって robots.txt の重要性が強調されました。
質問
先月、nextjs を使用して 2 つの Web サイトを構築しましたが、それ以来、それらに気を使っていません。最近、これら 2 つのサイトの Google への掲載状況が良くないことに気付きました。今日詳しく調べてみたところ、robots.txt に問題があることがわかりました。
GSCに含まれていないURLを確認した結果は以下の通り
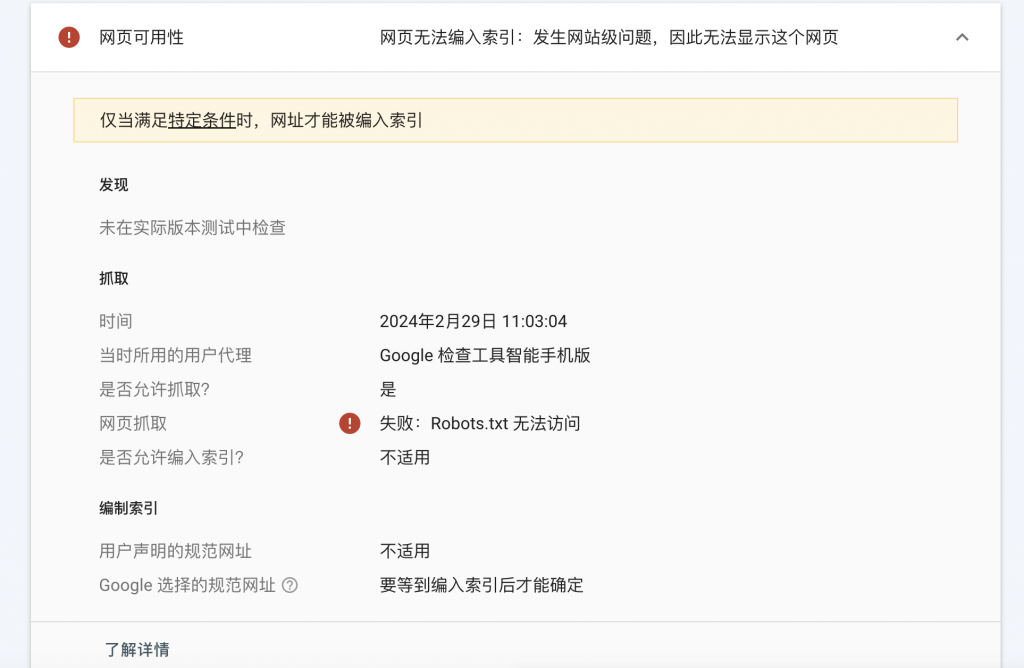
近年、Webサイトを構築する際にはWordPressなどの成熟したCMSを利用することが多く、robots.txtの問題を考慮する必要がなくなり、robots.txtは常に無視されてきました。
今回、nextjsを使ってWebサイトを構築したのですが、この問題に気づきました。
解決
robots.txt ファイルを追加します。
1. robots.txt ファイルを nextjs プロジェクトの app ディレクトリに追加します
2. 次のルールを robots.txt ファイルに追加します。
ユーザーエージェント: * 許可: / 禁止: /private/ サイトマップ: https://www.xxx.com/sitemap.xml例証します:
「User-Agent: *」: すべてのクローラーが Web サイトにアクセスできることを示します。
「許可: /」: すべてのコンテンツへのアクセスを許可します。
「Disallow: /private/」:プライベートディレクトリへのアクセスが許可されていないことを示します。
3. 完了後に再度テストします
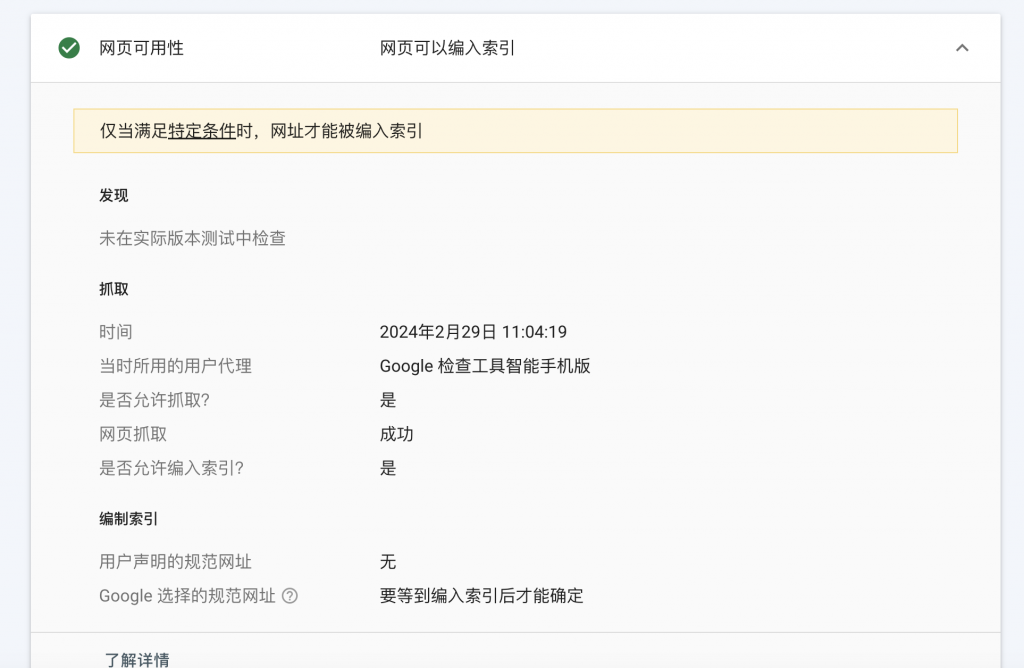
要約する
robot.txt ファイルが存在しないと、検索エンジンによるコンテンツの包含に大きな影響を与えます。
参照する
修正方法: Robots.txt によりデスクトップ ページがクロールされない – Google Merchant Center ヘルプ
メタデータ ファイル: robots.txt |Next.js (nextjs.org)

关注我的微信公众号
