robots.txt: проблема SEO, которая была проигнорирована.
вопрос
В прошлом месяце я использовал nextjs для создания двух веб-сайтов, но с тех пор ими не занимался. Недавно я обнаружил, что статус включения этих двух сайтов в Google не очень хороший. Сегодня я присмотрелся и обнаружил, что проблема в robots.txt.
Проверка URL-адреса, не включенного в GSC, результаты следующие:
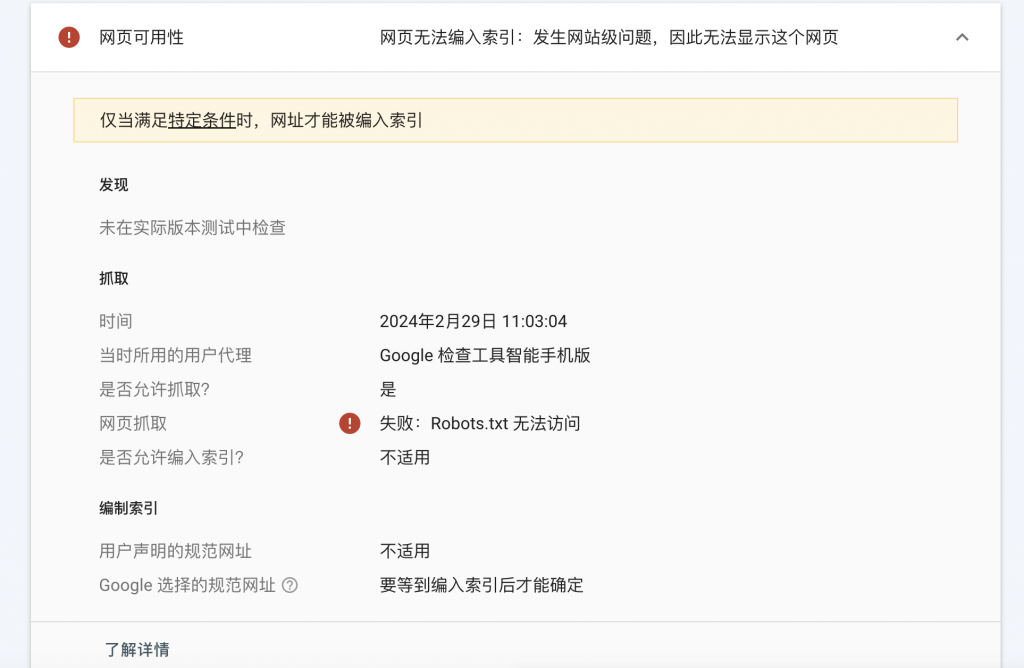
В последние годы при создании веб-сайтов большинство из них используют зрелые CMS, такие как WordPress и т. д., и нет необходимости учитывать проблему robots.txt. Поэтому robots.txt всегда игнорировался.
На этот раз я использовал nextjs для создания сайта и заметил эту проблему.
Решение
Добавьте файл robots.txt.
1. Добавьте файл robots.txt в каталог приложения проекта nextjs.
2. Добавьте следующие правила в файл robots.txt.
Пользовательский агент: * Разрешить: / Запретить: /private/ Карта сайта: https://www.xxx.com/sitemap.xmlпроиллюстрировать:
«User-Agent: *»: указывает, что все сканеры могут получить доступ к веб-сайту.
«Разрешить: /»: разрешает доступ ко всему содержимому.
«Disallow: /private/»: указывает, что доступ к частному каталогу запрещен.
3. Проверьте еще раз после завершения.
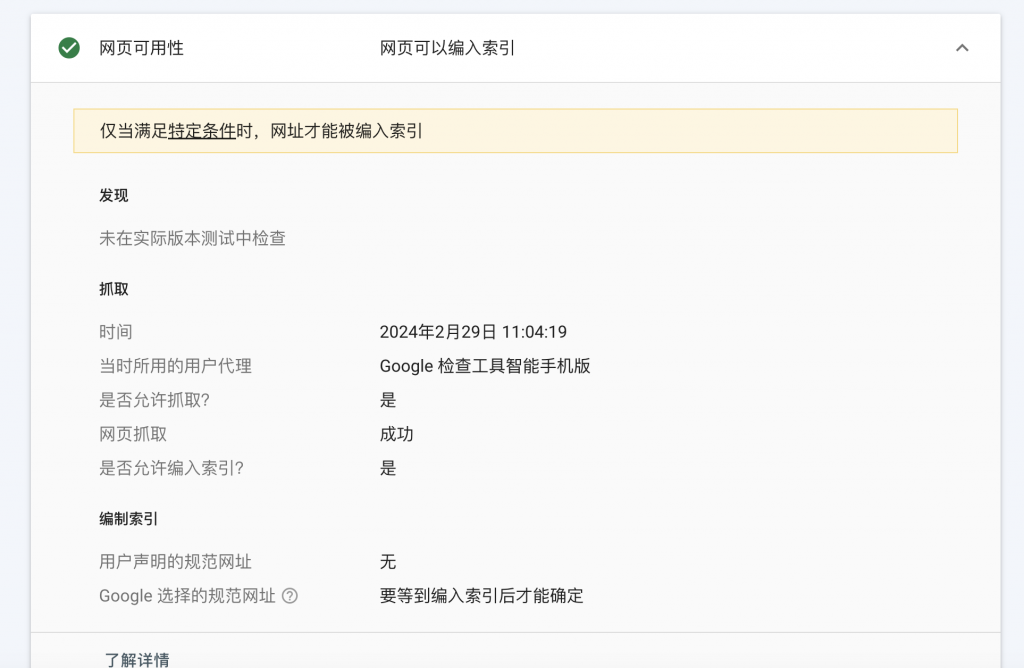
Подведем итог
Отсутствие файла robot.txt сильно повлияет на включение контента поисковыми системами.
Ссылаться на
Файл метаданных: robots.txt |Next.js (nextjs.org).

关注我的微信公众号
